







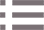
开云体育 
清华团队突破算力难开云体育官方题:4090显卡单枪匹马就能跑“满血版”DeepSeek-R1!有用户称整套方案成本不到7万元直降95%以上
 2025-10-06
2025-10-06 浏览次数:
次
浏览次数:
次 返回列表
返回列表开云体育[永久网址:363050.com]成立于2022年在中国,是华人市场最大的线上娱乐服务供应商而且是亚洲最大的在线娱乐博彩公司之一。包括开云、开云棋牌、开云彩票、开云电竞、开云电子、全球各地赛事、动画直播、视频直播等服务。开云体育,开云体育官方,开云app下载,开云体育靠谱吗,开云官网,欢迎注册体验!2月10日,清华KVCache.AI团队联合趋境科技发布KTransformers开源项目更新,支持24G显存在本地运行DeepSeek-R1、V3的671B“满血版”。更新发布后,不少开发者测试发现,显存消耗比技术文档中提到的还要少,实际内存占用约380G,显存占用约14G。有用户对方案成本进行分项分析后称,只要不到7万元就能实现R1模型的本地运行,与A100/H100服务器动辄200万元的价格相比,便宜了95%以上。不过,该方案也有诸多限制,如推理速度和适用模型等。
随着大规模语言模型(LLMs)的不断发展,模型规模和复杂性急剧提升,其部署和推理常常需要巨大的计算资源,这对个人研究者和小型团队带来了挑战。
KTransformers通过优化本地机器上的LLM部署,帮助解决资源限制问题。该框架采用了异构计算、先进量化技术、稀疏注意力机制等多种创新手段,提升了模型的计算效率,并具备处理长上下文序列的能力。
KTransformers的更新发布后,不少开发者也纷纷用自己的设备进行测试。他们惊喜地发现,本地运行完全没有问题,甚至显存消耗比github里的技术文档中提到的显存消耗还要少,实际内存占用约380G,显存占用约14G。
另外,有用户对方案成本进行分项分析后称,只要不到7万元就能实现R1模型的本地运行,与A100/H100服务器动辄200万元的价格相比,便宜了95%以上。
之前,671B参数的MoE架构大模型DeepSeek-R1经常出现推理服务器高负荷宕机的现象,而如果选择其他云服务商提供的专属版云服务器则需按GPU小时计费。这一高昂成本让中小团队无力承担,而市面上的“本地部署”方案多为参数量大幅缩水的蒸馏版。
但KTransformers开源项目近期的更新,成功打破了大模型推理算力门槛,支持24G显存在本地运行DeepSeek-R1、V3的671B“满血版”。
早在DeepSeek-V2时代,这一项目就因“专家卸载”技术出名了,因为它支持236B参数的大模型在仅有24GB显存的消费级显卡上流畅运行,把显存需求砍到十分之一。
KTransformers开源项目重点关注的就是在资源有限的情况下进行大模型的本地部署。一名KTransformers开发团队成员表示:“项目在创始之初就已经讨论过项目的场景和目标,我们所针对的是中小型用户的场景,用领域的话讲,就是低并发+超低显存的场景。而显存目前的成本已经和CPU的内存不是一个数量级了,对于中小用户内存可能完全不缺,但是找一个显存很大的显卡却很难。”
KTransformers的原理大致为将参数较少、计算比较复杂的MLA注意力放在GPU上进行计算,而参数大的、计算比较轻松的FNN(MOE)则放到CPU上去计算。
MoE结构的模型具有很强的稀疏性,在执行推理任务的时候,每次只会激活其中一部分的模型参数。因此,MoE架构需要大量的存储空间,但并不需要很多的计算资源。在这样的情况下,同样使用4bit量化,只需要一个4090 GPU就可以满足这个参数需求。
此外,KTransformers团队还公布了v0.3预览版的性能指标,将通过整合英特尔的AMX指令集,CPU预填充速度最高至286 tokens/s,相比llama.cpp快了近28倍。对于需要处理上万级Token上下文的长序列任务来说,相当于能够从“分钟级等待”瞬间迈入“秒级响应”,彻底释放CPU的算力潜能。
KTransformers的更新发布后,不少开发者也纷纷在自己的设备上进行测试。他们惊喜地发现,本地运行完全没有问题,显存消耗甚至比github里的技术文档中提到的还要少,实际内存占用约380G,显存占用约14G。
有B站up主实测发现,本地部署的速度可以达到约6-8 tokens/s,与硅基流动免费版速度差不多(但硅基流动有上下文关联数、输出数限制等因素)。
显卡:低档4060Ti 16G,大概3999元。更加建议4090 24G,因为可以增加上下文长度。
该用户总结称,整体成本7万元不到,相比于A100/H100服务器动辄200万元的价格,便宜了95%以上。就算是租用服务器每小时也得花费数千元。
当然,这一本地方案还是有着诸多的限制,比如推理速度并不能和高价的服务器成本相提并论,并且只能给单人服务,而服务器可以同时满足几十个用户的需求。目前整体方案也依赖于英特尔的AMX指令集,其他品牌的CPU暂时还无法进行这些操作。并且这一方案主要是针对DeepSeek的MOE模型,其他主流模型的运行可能并不理想。
有用户认为,短期来看,KTransformers可能刺激消费级显卡(如4090)的需求,尤其是高显存型号。但内存涨价的可能性较低,因为其核心创新在于优化显存利用率,而非直接增加内存消耗。但对于英伟达的影响并不会太大,因为这一技术归根结底还是对于现有资源的优化而非颠覆硬件需求。
免责声明:本文内容与数据仅供参考,不构成投资建议,使用前请核实。据此操作,风险自担。
如需转载请与《每日经济新闻》报社联系。未经《每日经济新闻》报社授权,严禁转载或镜像,违者必究。
特别提醒:如果我们使用了您的图片,请作者与本站联系索取稿酬。如您不希望作品出现在本站,可联系我们要求撤下您的作品。
阿里云百炼上线全尺寸DeepSeek模型,1元最高可享受200万tokens
工信部:三大运营商均全面接入DeepSeek大模型;三星全球多区高管换血|数智早参
青羊经开区“进高校、链资源、促转化”人才科技交流对接活动走进西北工业大学
陈震车祸比亚迪车主妻子发声:丈夫多处骨折!陈震回应:全力配合、做好后续工作、补偿损失
哈马斯代表团将与以色列谈判,人员交换与停火条件成焦点!特朗普:不明白内塔尼亚胡为何总是那么消极
特朗普头像将登上1美元硬币,而且正反面都是他?美财政部官员:这不是假消息
